

{kind=link}
Briefly
- Google launched DiffusionGemma, a free open-weight mannequin that generates complete 256-token blocks concurrently by way of textual content diffusion—hitting over 1,000 tokens per second on an NVIDIA H100, 4 occasions sooner than customary autoregressive fashions.
- The customized drafter module DiffusionGemma wants for native inference would not exist in any public runtime but—not in mlx-lm, not in LM Studio—making it successfully unrunnable on most shopper setups at this time.
- On NVIDIA NIM, the mannequin arrived preconfigured at 8,192 tokens of context—beneath the 64,000-token flooring that agentic frameworks like Hermes Agent require—which means autonomous workflows will not run with out handbook reconfiguration.
Google dropped DiffusionGemma at this time, an open mannequin AI that generates textual content the way in which picture mills create footage: begin with noise, refine till it is smart. It hits 1,000 tokens per second on an NVIDIA H100. (Tokens are the essential unit of data that an AI mannequin handles.) Which means it’s 4 occasions sooner than common Gemma. It’s additionally free, Apache 2.0, with weights on Hugging Face.
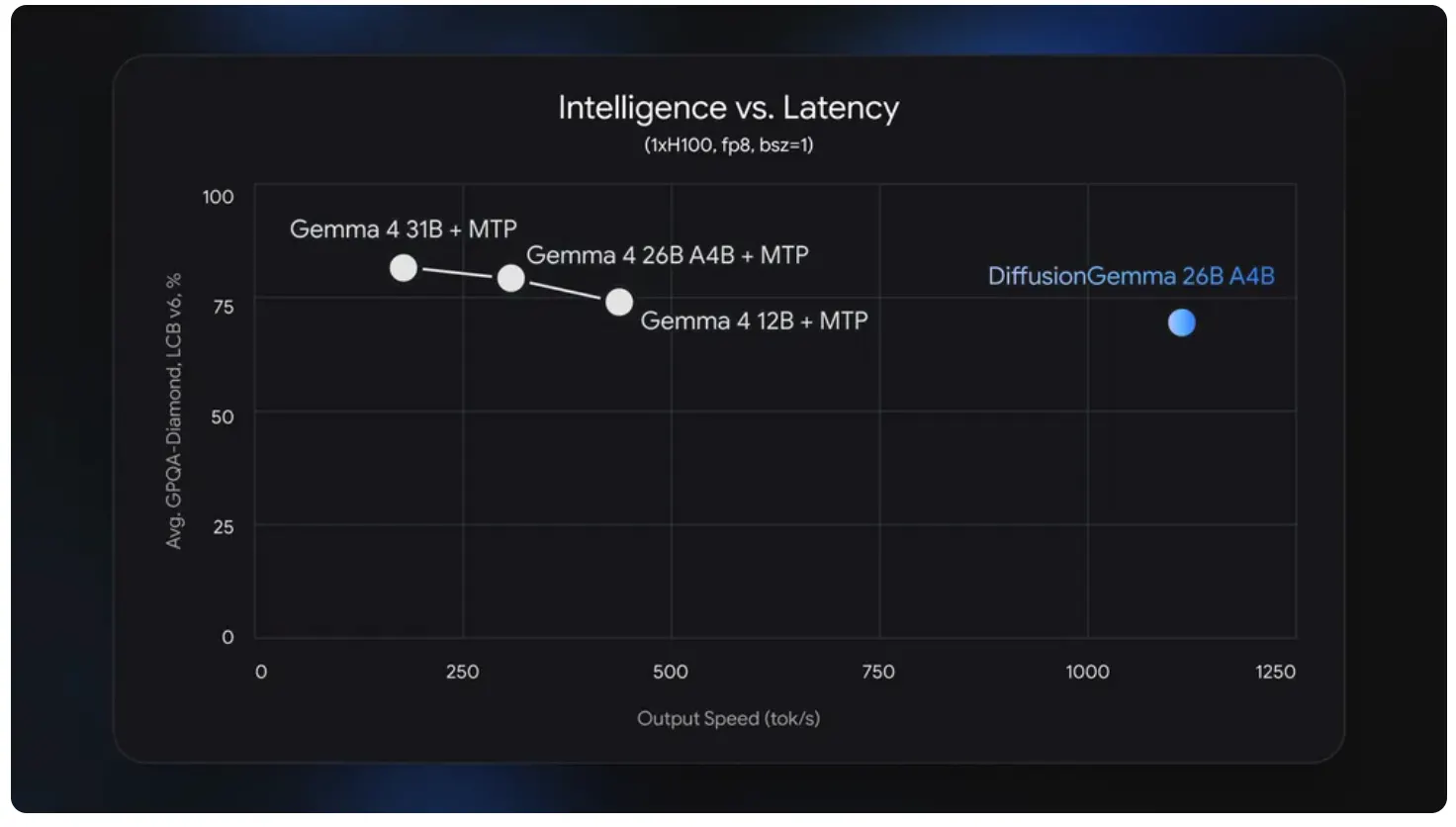
The catch, as all the time, is within the high quality print. Per Google’s announcement, the mannequin hits “700+ tokens per second on NVIDIA GeForce RTX 5090.” It additionally trails customary Gemma 4 on output high quality.
Google says so themselves. This can be a velocity mannequin, not a top quality improve.
What this really does
Each LLM you have used is a typewriter. One token at a time with every phrase depending on the final. That is how autoregressive architectures work.
DiffusionGemma would not try this. As an alternative of producing tokens sequentially, it begins with refined chunks of garbled textual content in parallel. Per Google’s developer information, it “begins with a canvas of random placeholder tokens” and iteratively locks in assured tokens till the entire block snaps into focus. 2 hundred fifty-six tokens per ahead move. The GPU stays busy.

The aspect impact is bidirectional consideration—each token can see each different token whereas being generated, which is unimaginable in autoregressive fashions (they can’t see the long run, what will be encoded). That makes it unusually good at duties the place the tip of the reply constrains the start: code infilling, structured output, constraint-heavy issues, and many others. Google fine-tuned a model to unravel Sudoku as a demo. The bottom mannequin acquired roughly 0% of puzzles proper.
The fine-tuned model hit 80%.
Textual content diffusion has been a analysis venture for years. MDLM, SEDD, LLaDA, Dream—tutorial fashions that proved the strategy labored at small scales and principally stayed as proof of ideas. Inception Labs shipped Mercury 2 in February 2026 as the primary industrial diffusion reasoning mannequin, claiming speeds 5 occasions sooner than speed-optimized rivals.
However none of that was open-weight, and none of it got here with day-zero assist in vLLM, Hugging Face Transformers, and Unsloth. DiffusionGemma is the primary main open launch from a tier-one lab.
There’s additionally a historic irony value noting. Picture mills began as diffusion fashions (therefore the title Steady Diffusion) and are actually shifting towards autoregressive architectures for higher high quality. Language fashions began as autoregressive and are actually experimenting with diffusion for velocity.
Why it’s a ache to run… for now
Working DiffusionGemma effectively requires a drafter—a light-weight module that proposes token blocks in parallel, which the primary mannequin then verifies in a single ahead move. That is referred to as speculative decoding. DFlash is a framework printed in early 2026 that makes use of a small diffusion mannequin because the drafter, enabling over 6x speedup on some duties. It is the engine that makes this class of mannequin sensible.
The issue: DiffusionGemma wants a selected drafter to run regionally by way of MLX—Apple’s machine studying framework for Apple Silicon. That module would not exist in any public model of mlx-lm, in any open pull request, or in LM Studio’s bundled runtime.
We tried operating DiffusionGemma with Hermes by way of NVIDIA NIM. The mannequin loaded, however then: “agent init failed: Mannequin google/diffusiongemma-26b-a4b-it has a context window of 8,192 tokens, which is beneath the minimal 64,000 required by Hermes Agent.”
To be exact: DiffusionGemma’s precise context window is 256K tokens. The 8,192 determine was Nvidia messing issues up by default, not the mannequin’s architectural restrict.
In follow, getting it configured appropriately for agentic use requires handbook work that almost all on a regular basis customers have not found out but, and Hermes Agent merely will not initialize with out it. Parallel velocity means nothing if the agent cannot boot.
Hopefully, within the subsequent few days, the neighborhood will produce higher sources to run these fashions.
Who that is really for
Builders with NVIDIA RTX 4090 or 5090 {hardware} constructing real-time instruments—inline editors, autocomplete, code infilling, structured era. That is the goal. As Decrypt coated in Might, Google has been on a gradual push to make native inference sooner with out new {hardware}.
For researchers, bidirectional era opens territory that autoregressive fashions merely cannot attain—protein sequences, mathematical graphs, something the place place N is determined by place N+50. That is not a small factor.
Google launched Gemma 4 below Apache 2.0 in April, and DiffusionGemma continues that technique. There’s already a draft llama.cpp PR open as of at this time. When the toolchain catches up, this reaches a a lot wider viewers.
On a machine with a succesful discrete GPU, 1,000 tokens per second is actual.
Every day Debrief E-newsletter
Begin on daily basis with the highest information tales proper now, plus unique options, a podcast, movies and extra.